Cuando se trata de la estructura de la base de datos, las empresas básicamente tienen dos opciones: relacional (SQL) o no relacional (NoSQL). La primera organiza los datos en una serie de tablas y tienen un esquema predefinido, mientras que la segunda tiene un esquema dinámico para datos no estructurados. ¿Pero cuál es mejor?.
Con el auge de la tecnología de nube y contenedores, el sistema de base de datos relacional y de código abierto PostgreSQL (o Postgres, como se le llama cariñosamente) está mostrando una notable versatilidad. A pesar de haber existido durante más de tres décadas, no teme aprender nuevos trucos de sus primos NoSQL más jóvenes.
¿Qué importancia tienen las bases de datos relacionales en la era de NoSQL?
NoSQL significa “No solo SQL”, y eso explica por qué Postgres es el claro ganador en la clasificación de DB-Engines, en la encuesta de desarrolladores de Stackoverflow.
Postgres, a diferencia de otras bases de datos relacionales, se basa en una arquitectura relacional de objetos. Es por eso que es líder en la combinación de datos relacionales con datos geoespaciales, pares clave-valor, datos de documentos y tipos de datos personalizados.
Esta decisión clave de diseño, tomada por Mike Stonebraker hace más de 25 años, está impulsando la rápida adopción de Postgres por parte de desarrolladores y administradores de bases de datos. La clasificación de DB-Engines muestra que la adopción de Postgres supera a MongoDB.
Las bases de datos que son relacionales no muestran tendencias de adopción similares y pueden perder relevancia con el tiempo.
EDB ha sido una fachada comercial de Postgres desde principios de la década de 2000. ¿Qué cambios ha tenido la llegada de los servicios nativos de la nube en las bases de datos tradicionales como PostgreSQL a lo largo de los años?
Postgres ha pasado la prueba del tiempo sorprendentemente bien. De hecho, la herencia de Postgres ayuda a fortalecerla a medida que madura. Es la base de datos número uno en contenedores y un componente clave de todos los servicios de base de datos de los proveedores de la nube. Las ofertas nativas de la nube, como el operador Cloud Native Postgres de EDB para Kubernetes, continúan el impulso para hacer Postgres más fácil y más accesible para una audiencia más amplia.
Muchas bases de datos tradicionales, comerciales y patentadas han experimentado una disminución, pero Postgres ha experimentado un tremendo crecimiento en paralelo con la nube. El hecho de que Postgres sea de código abierto, rentable, innovador, poderoso y extremadamente confiable ha contribuido a ese crecimiento. Postgres también se ejecuta en todas partes bajo la misma licencia permisiva, que es otra razón de su creciente popularidad.
Postgres, el código abierto y la adopción de la nube, junto con Kubernetes y los microservicios, tienen una cosa en común: innovación rápida impulsada por la necesidad de transformación digital, alta velocidad de funciones y un mejor ajuste del mercado de productos.
El cambio clave que hemos visto es la maduración de la infraestructura como código, ya sea a través de operadores de Kubernetes o mediante herramientas como Ansible, que permiten implementaciones de Postgres rápidas y repetibles en las instalaciones, en la nube y en entornos DevOps.
Una de las ventajas que las bases de datos NoSQL afirman sobre las relacionales es el escalado. ¿Cómo ha evolucionado Postgres en este aspecto?
Más del 95% de todas las bases de datos actuales encajan cómodamente en los servidores informáticos avanzados que están disponibles hoy en la nube o en las instalaciones. Muy pocas aplicaciones realmente necesitan escalado horizontal en un momento en que 96 núcleos o más están disponibles de forma rutinaria en la nube y en la mayoría de los centros de datos. Un argumento presentado históricamente por los defensores de la escala horizontal ha sido que es difícil escalar la computación y la memoria hacia arriba y hacia abajo.
La infraestructura como tecnología de código, como Kubernetes y Ansible, hace que la ampliación de la CPU y los recursos de memoria sea muy fácil y rápida, mucho más fácil y rápida que la ampliación.
Además, tenga en cuenta que escalar a varios servidores significa agregar una latencia significativa, ya que más datos viajan a través de la red, que es mucho más lento que el backplane de un servidor o el bus de datos de un chip moderno de alta densidad.
Al mismo tiempo, con la llegada de los microservicios, vemos muchos más diseños “inteligentes” que refactorizan bases de datos de gran tamaño en arquitecturas más pequeñas e inteligentes. Es mucho más fácil resolver problemas por adelantado con un buen diseño, en lugar de intentar solucionarlos después lanzándoles hardware. Afortunadamente, Kubernetes y los microservicios fomentan los diseños inteligentes.
¿Cuáles son algunos aspectos en los que las bases de datos relacionales en general y PostgreSQL en particular puntúan sobre las bases de datos NoSQL?
A menudo, NoSQL se utiliza como sinónimo de “consistencia eventual”, y relacional realmente pretende significar “ACID” (atómico, consistente, aislado, duradero). Las bases de datos que cumplen con ACID son altamente confiables y los resultados de las operaciones en estos entornos son altamente predecibles. Eso es clave para las transacciones comerciales, las operaciones contables y cualquier otra tarea de administración de datos que requiera un 100% de confiabilidad. Además, la mayoría de las herramientas analíticas están diseñadas para trabajar con tablas y relaciones.
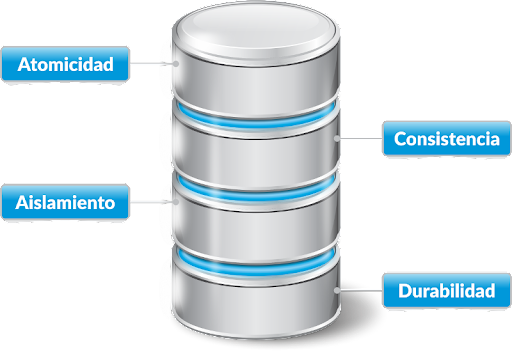
A menudo, los formatos NoSQL, como los documentos, deben mapearse primero en estructuras tabulares para realizar análisis. Esto también es cierto para la reducción de mapas, que toma datos no estructurados y los coloca en un formato tabular y relacional estructurado para admitir consultas.La naturaleza del modelo relacional, especialmente el uso de formas normales, proporciona al desarrollador una herramienta muy poderosa para evitar la redundancia de datos y crear modelos de datos que no son específicos de un solo caso de uso.
Con más y más organizaciones adoptando una estrategia de múltiples nubes y mezclando sus bases de datos en la nube con las alojadas en las instalaciones, ¿qué tan bien se presta PostgreSQL a un entorno tan interoperable?
Postgres ha elegido la capa de abstracción de la Interfaz del sistema operativo portátil (POSIX) como su interfaz con el sistema operativo. Eso le permite ejecutarse prácticamente en todas partes y explica por qué funciona en cada nube, en contenedores, con todos los sistemas operativos clave y con prácticamente todas las plataformas de hardware. EDB tiene muchos clientes que han decidido estratégicamente desarrollar contra la API de Postgres, ya que les permite crear aplicaciones que se pueden implementar donde sea necesario.A diferencia de otras bases de datos comerciales que limitan algunas de sus características para alta disponibilidad a su propia nube, no existen tales restricciones con Postgres. EDB Postgres ofrece el mismo Postgres siempre activo y de alta disponibilidad en todas las plataformas, no solo en algunas líneas de hardware seleccionadas o nubes propietarias.
Esta portabilidad extrema hace de Postgres la plataforma ideal para estrategias híbridas o de múltiples nubes.
EDB tiene una relación simbiótica con la comunidad de código abierto PostgreSQL desde el principio. ¿Qué importancia tiene esta relación para los proveedores comerciales con un modelo de negocio basado en software de código abierto?
Nada de lo que EDB hace sería posible sin una comunidad de Postgres vibrante, independiente e innovadora. EDB es un firme partidario de la comunidad. Los desarrolladores de EDB casi 30 EDBers de tiempo completo son nombrados como contribuyentes, comprometidos o miembros del equipo central de Postgres, y con una comunidad de 300 programadores dedicados a Postgres o debería decir fanático. Ser fanáticos de Postgres significa estar implacablemente comprometidos a continuar la inversión en software de código abierto y la comunidad en la que otras organizaciones como Microsoft, VMWare, NTT, Fujitsu participan en la creación de la tecnología de código abierto más transformadora desde Linux.
Es así como cierro este artículo, dejando en el lector la inquietud de pensar cómo esta transformación desarrollada desde bases construidas hace más de 25 años puede hoy estar siendo el comienzo de un nuevo modelo para la gestión de datos.
